Son olarak TensorRT’nin seçeneklerinden biri de bir modelle en uygun yolu ayarlayabilmenizdir Başka bir deyişle, daha yeni mimariler daha yetenekli olmalıdır; ancak Kararlı Yayılımda gerekli olan iş türü çoğunlukla ham bilgi işlem ve bellek bant genişliğine dayanıyor gibi görünmektedir ONNX, AI modellerinin çok çeşitli arka uçlarla kullanılmasına izin verecek şekilde tasarlanmıştır: PyTorch, OpenVINO, DirectML, TensorRT, vb Nvidia’nın en yeni GPU’larından bazılarını TensorRT kullanarak test ettik ve Stabil Difüzyon performansının %70’e kadar arttığını gördük Otomatik1111 DirectML şubesive bu tamamlandığında güncellenmiş bir Kararlı Yayılım özetine sahip olacağız 5, Nvidia’nın en yeni sürücüleriyle birlikte sunulmaktadır İkincisi, 1080p monitörde 1080p yayın izliyorsanız, VSR’nin gürültü giderme ve görüntü iyileştirme konusunda yine de yardımcı olabileceği anlamına gelir
Nvidia, AI/ML (Yapay Zeka/Makine Öğrenimi) ve LLM (Geniş Dil Modeli) araçları paketinde daha fazla iyileştirme üzerinde çalışmakla meşgul TensorRT şu adresten indirilebilir olmalıdır: Nvidia’nın Github sayfası şimdi, bu ilk bakışın amaçları doğrultusunda erken erişime sahiptik AMD ve Intel modellerinde de daha fazla ayarlama yapılmasını bekliyoruz, ancak zamanla kazanımların azalması muhtemeldir
Ancak güncellenen yerel verilerle daha anlamlı bir yanıt verebiliyor Kendi bilgilerinizi kullanarak potansiyel olarak daha akıllı bir arama seçeneğidirNvidia’nın verdiği bir başka örnek de bu tür yerel verileri kendi e-postanız veya sohbet geçmişinizle kullanmaktı
Nvidia’nın en yeni RTX 40 serisi GPU’larının tümünü ayarlama sürecinden geçirdik (optimum performans için her birinin ayrı ayrı yapılması gerekiyor), ayrıca Xformers kullanarak temel Stabil Difüzyon performansını ve performansını test ettik
Resim 1 ile ilgili 3
(İmaj kredisi: Tom’un Donanımı) (İmaj kredisi: Tom’un Donanımı) (İmaj kredisi: Tom’un Donanımı)Resim 1 ile ilgili 3
(İmaj kredisi: Tom’un Donanımı) (İmaj kredisi: Tom’un Donanımı) (İmaj kredisi: Tom’un Donanımı)512×512 ve 768×768 boyutlarındaki yukarıdaki galerilerin her biri, Stabil Difüzyon 1 Bu durumda işler Alan Wake 2 açıklanmış resmi bir bilgi yok AI ve ML modelleri ve operatörleri için açık bir format olan ONNX’ten yararlanan temel Hugging Face kararlı dağıtım modeli, bir ONNX formatına dönüştürülür
Genel verimde çeşitli faktörler rol oynar
İlginç olan, (şu ana kadar test edilen GPU’lar arasında) en küçük kazancın RTX 3090’dan gelmesi
Temel fikir, AMD ve Intel’in halihazırda yaptıklarına benzer
Kullanılan model formatına bağlı olarak göreceli performansta bazı mütevazı farklılıklar vardır
TesorRT-LLM henüz çıkmadı ancak şu tarihte mevcut olması gerekiyor: geliştirici ONNX bu sürecin basitleştirilmesine yardımcı olur; bu nedenle AMD (DirectML) ve Intel (OpenVINO) tarafından Kararlı Difüzyonun ayarlanmış dalları için kullanılmıştır AMD GPU’ların en yeni sürümlerle tam olarak test edilmesi üzerinde çalışıyoruz
Grafiğin gösterdiği gibi, tek bir metin kümesi oluşturmanın mütevazı bir faydası var, ancak bu durumda GPU (RTX 4090) tam anlamıyla çalışmıyor gibi görünüyor
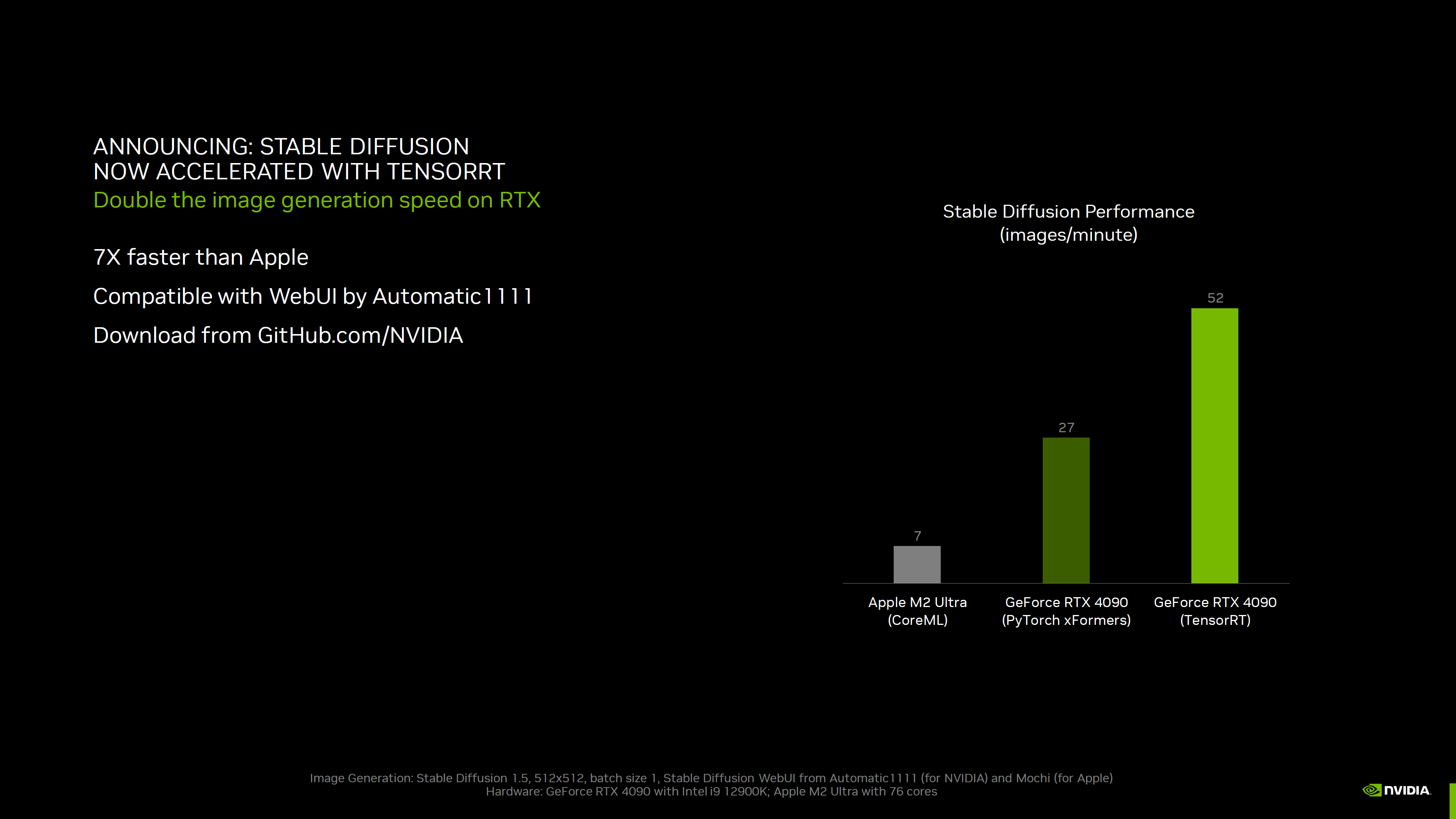
(Resim kredisi: Nvidia)Peki TensorRT’de performansı bu kadar artırabilecek tam olarak neler oluyor? Bu konu hakkında Nvidia ile konuştum ve konu çoğunlukla kaynakların ve model formatlarının optimize edilmesiyle ilgiliydi Artık Nvidia, TensorRT ile aradaki farkı yeniden genişletmeye hazır
Temel model, anlamlı cümlelerin nasıl oluşturulacağı vb L2 önbellek boyutları da bunu hesaba katabilir, ancak bunu doğrudan modellemeye çalışmadık Bizim durumumuzda 512×512 ve 768×768 boyutunda toplu resimler yapıyoruz TensorRT’nin bazı şeyleri ayarlaması birkaç dakika (veya bazen daha fazla) alır, ancak tamamlandığında, daha iyi bellek kullanımıyla birlikte performansta önemli bir artış elde etmelisiniz Tüm Yüksek Lisans’larda olduğu gibi, eğitim verilerine ve sorduğunuz sorulara bağlı olarak sonuçların kalitesi biraz değişken olabilir nvidia Bu, modellerin çeşitli yapay zeka hızlandırma çerçeveleri arasında kolayca taşınmasına olanak tanır
Bunu kendi HammerBot’umuz için potansiyel bir kullanım durumu olarak görmeden edemeyiz, ancak bunun kendi sunucularımızda kullanılabilir olup olmadığını görmemiz gerekecek (çünkü bir RTX kartına ihtiyaç duyuyor) İçerik oluşturucu topluluğu genellikle 1,5 sonuçlarını tercih ettiğinden 2,1 yerine 1,5 kullanmaya “geri döndük”, ancak sonuçların yeni modellerle hemen hemen aynı olması gerekiyor Sınırlayıcı faktörün ne olabileceği tam olarak belli değil, ancak kesin bir sonuca varmak için ek GPU’ları test etmemiz gerekecek Bu, yedi milyar parametreye sahip bir metin oluşturma aracıdır
(Resim kredisi: Nvidia)Nvidia ayrıca, artık RTX 20 serisi GPU’ları destekleyen ve yerel yapıyı azaltan Video Süper Çözünürlüğüne yönelik güncellemeleri de duyurdu konularda tüm bilgileri sağlar, ancak son olaylar veya duyurular hakkında hiçbir bilgisi yoktur
ONNX, başlangıçta Facebook ve Microsoft tarafından geliştirildi ancak Apache Lisans modelini temel alan açık kaynaklı bir girişimdir
Bunu tam Nvidia ile dünya performans karşılaştırması yapmaya çalışmıyoruz, ancak örnek olarak RX 7900 XTX’in güncellenmiş testi, 512×512 için dakikada yaklaşık 18~19 görüntü ve 768×768’de dakikada yaklaşık beş görüntü ile zirveye çıkıyor O zamandan bu yana, görüntü yapay zekası oluşturma araçlarına alternatif metin ve çatalların sayısında patlama yaşandı ve hem AMD hem de Intel, Nvidia’nın performansıyla aradaki farkı bir miktar kapatan daha ince ayarlı kitaplıklar yayınladı Bunun neler yapabileceğine bir örnek olarak, Nvidia, araca 30 yeni Nvidia haber makalesini aktardı ve temel Llama 2 modeli ile model arasındaki yanıt farkını bu yerel verilerle görebilirsiniz
(Resim kredisi: Nvidia)Son olarak, Yüksek Lisans’lara yönelik yapay zeka odaklı güncellemelerin bir parçası olarak Nvidia, Llama 2’nin temel model olarak kullanılmasına ve ardından daha alana özel ve güncel bilgi için yerel verilerin içe aktarılmasına olanak sağlayacak bir TensorRT-LLM aracı üzerinde de çalışıyor
(Resim kredisi: Nvidia)Güncellenen TensorRT elbette yalnızca Kararlı Difüzyon için geçerli değil VRAM kapasitesi, potansiyel olarak daha büyük görüntü çözünürlüğü hedeflerine veya toplu boyutlara izin vermekten başka, daha küçük bir faktör olma eğilimindedir; başka bir deyişle, 24 GB VRAM ile yapabileceğiniz, ancak 8 GB ile mümkün olmayacak şeyler vardır TensorRT kazanımlarının Nvidia’nın tüm RTX serisine nasıl uygulandığını göstermek için bir RTX 30 serisi (RTX 3090) ve bir RTX 20 serisi (RTX 2080 Ti) ekledik
AMD’nin DirectML çatalının bazı benzer seçenekleri var, ancak şu anda karşılaştığımız bazı sınırlamalar var (örneğin, birden fazla toplu iş boyutu yapamıyoruz) Söyleyebileceğimiz şey, temelde aynı özelliklere sahip olan (16GB’taki özel model nedeniyle biraz farklı saatler) 4060 Ti 16GB ve 8GB kartların neredeyse aynı performansa ve optimum parti boyutlarına sahip olduğudur Ürettiğimiz genel TensorRT modeli, 512×512 ila 1024×1024 dinamik görüntü boyutuna, toplu iş boyutu bir ila sekize ve optimum 512×512 yapılandırmasına ve toplu iş boyutu 1’e sahip olabilir
Geçtiğimiz yıl boyunca Kararlı Difüzyonda çok fazla hareket gördük Nvidia, TensorRT kullanarak Llama 2 7B int4 çıkarımıyla ölçtüğü iyileştirmeleri detaylandıran yukarıdaki slaydı paylaştı TensorRT daha sonra performansı 512×512’de yüzde 50~65 ve 768×768’de yüzde 45~70 oranında artırır Temel model en yavaş olanıdır; Xformers performansı 512×512 görüntüler için yüzde 30 ila 80 arasında ve 768×768 görüntüler için yüzde 40 ila 100 arasında artırır En yeni optimize edilmiş araçları kullanarak bir dizi ek GPU’yu yeniden test ettiğimiz için AMD, Intel ve Nvidia’nın Stable Diffusion’daki performansını karşılaştıran tam güncellemeye tam olarak hazır değiliz, bu nedenle bu ilk görünüm yalnızca Nvidia GPU’lara odaklanıyor İlk bakışımız kullanıldı Otomatik1111’in web arayüzüBaşlangıçta yalnızca Windows altında Nvidia GPU’ları destekliyordu RTX 40 serisinde dördüncü nesil Tensor çekirdekleri, RTX 30 serisinde üçüncü nesil Tensor çekirdekleri ve RTX 20 serisinde ikinci nesil Tensor çekirdekleri bulunur (Volta mimarisi birinci nesil Tensor’dur)
Bu arada TensorRT, Nvidia GPU’larında daha performanslı olacak şekilde tasarlandı TensorRT’nin avantajlarından yararlanmak için bir geliştiricinin normalde modellerini doğrudan TensorRT’nin beklediği formata yazması veya mevcut bir modeli bu formata dönüştürmesi gerekir Bellek bant genişliği gibi GPU hesaplaması da oldukça önemlidir 5 modellerini kullanır Bu durumda daha büyük toplu iş boyutları, birden fazla metin yanıtı oluşturmak için kullanılabilir; bu, kullanıcının tercih ettiği yanıtı seçmesine, hatta yararlıysa çıktının bölümlerini birleştirmesine olanak tanır Daha sonra genel oranı belirlemek için üç ayrı çalışmanın veriminin ortalamasını aldık; böylece her model formatı ve GPU için toplam 72 görüntü oluşturuldu (atılan çalıştırmalar hariç) Yani yapabiliriz bir diğer Özellikle 512x512x8 veya 768x768x4 veya her neyse hedefleyen TensorRT modeli Daha sonra ona şu tür şeyler sorabilirsiniz: “Chris ve ben geçen yıl hangi filmden bahsediyorduk?” ve bir cevap verebilirdi Her GPU için, optimum verimi bulmak amacıyla farklı toplu boyutlar ve toplu sayımlar çalıştırdık ve çalıştırma başına toplam 24 görüntü oluşturduk VSR 1 En son eklenen TensorRT ve TensorRT-LLM, tüketici GPU’larının ve Stable Diffusion ve Llama 2 metin oluşturma gibi görevleri yürütmek için en iyi grafik kartlarının çoğunun performansını optimize etmek üzere tasarlandı Toplu iş boyutunun dörde çıkarılması genel verimi 3,6 kat artırırken, toplu iş boyutunun sekiz olması 4,4 kat hızlanma sağlar